Hola, os dejo una guía paso a paso para poder probar Apache Spark a partir de la instalación de una máquina virtual en vuestro equipo. Los requisitos mínimos son los siguientes:
- Un equipo con más de 2Gb de memoria
- Sistema operativo Windows, Linux o Mac
- VirtualBox
- Una máquina virual con todo el software necesario ya configurado.
- Ganas de explorar lo desconocido ;-)
Ahí vamos… El primer paso es descargar la aplicación VirtualBox (https:/www.virtualbox.org), en el caso de que no se tenga previamente instalada en el equipo.

Una vez descargado el fichero, se debe de instalar VirtualBox en el equipo y ejecutarlo (necesitareis permisos de administrador).
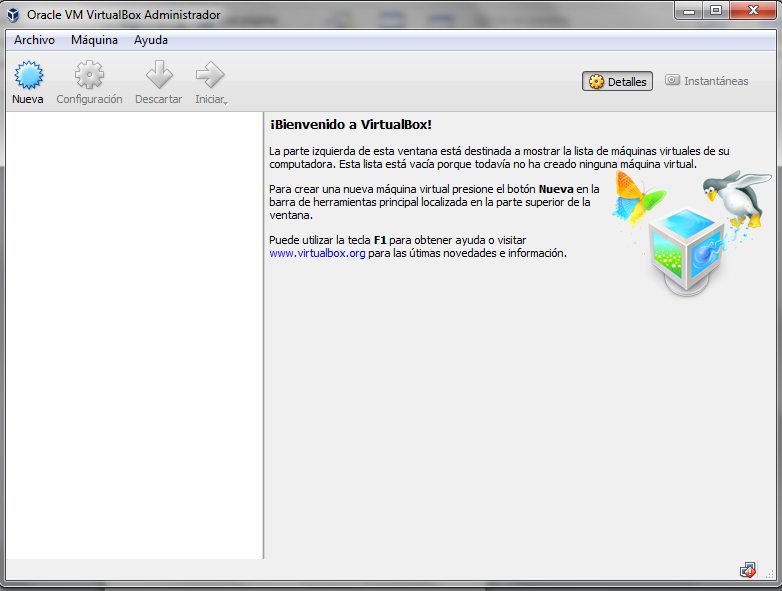
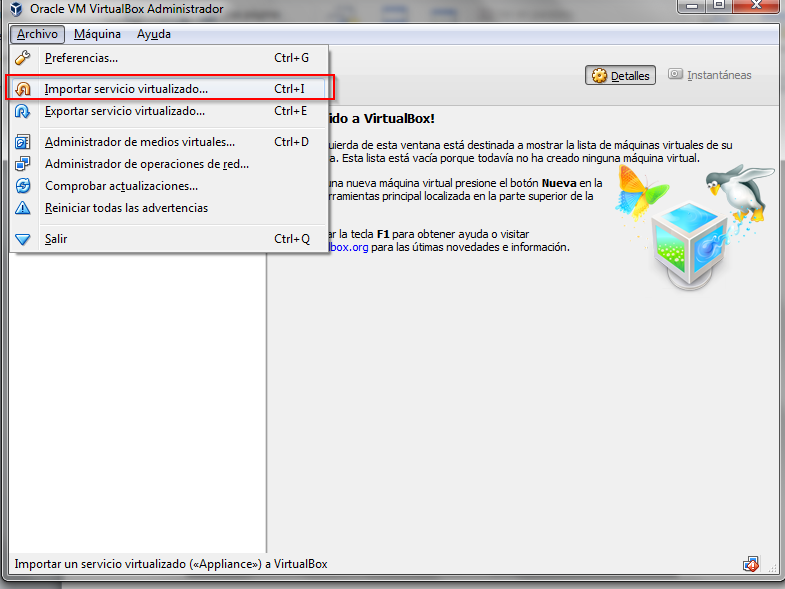
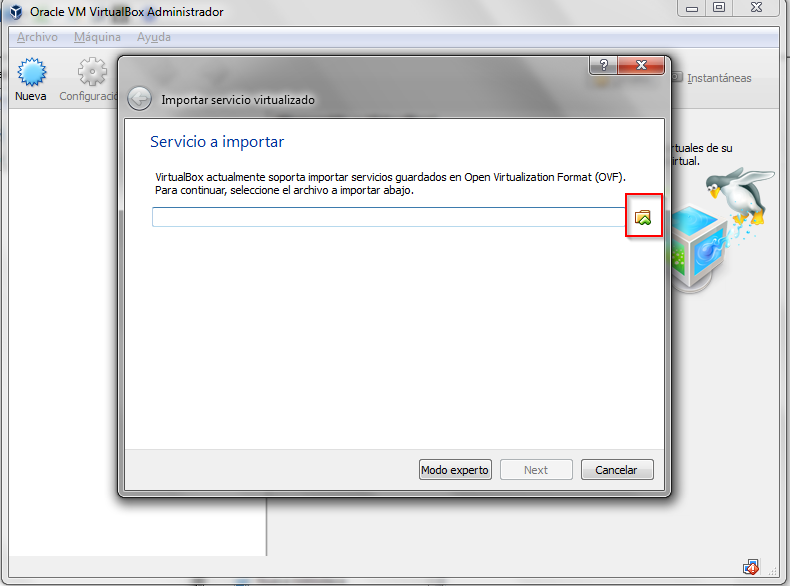
Una vez en VirtualBox, hay que importar el fichero sparkvm.ova, desde la opción “Importar servicio virtualizado” del menú Archivo:
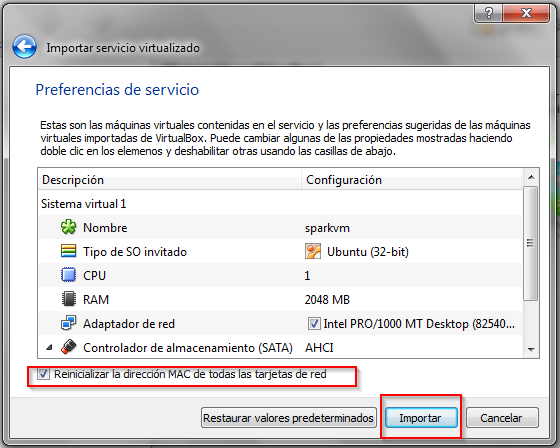
Cuando finalice la importación, se tiene pulsar el botón “Iniciar” para ejecutar la máquina virtual y probar Spark.
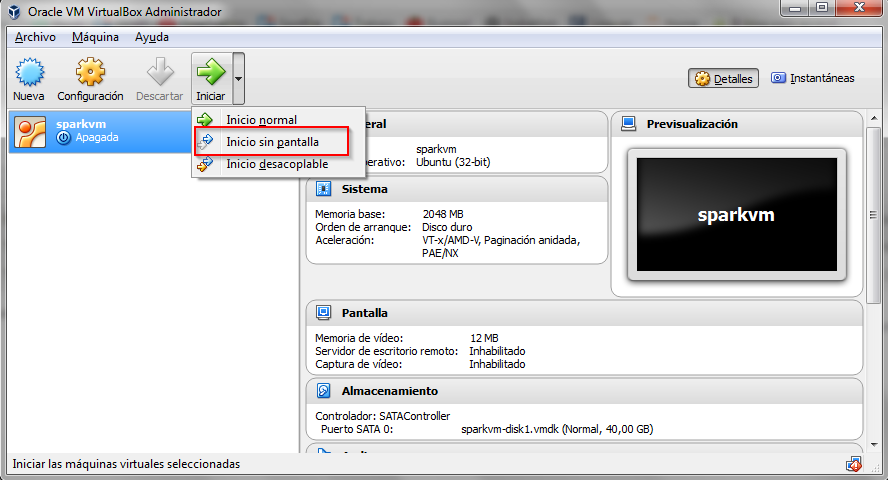
Con la opción “Inicio sin pantalla” es suficiente, ya que la forma de probar Spark es a través del navegador, y no necesitamos tener la consola activa.
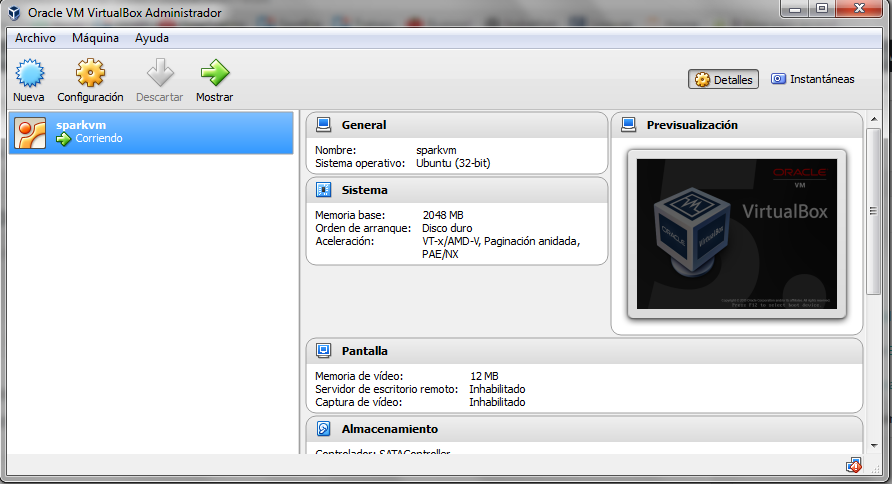
Se abre un navegador y se accede a la dirección http://localhost:8001, donde está desplegado Jupyter sobre la máquina virtual que acabamos de instalar.
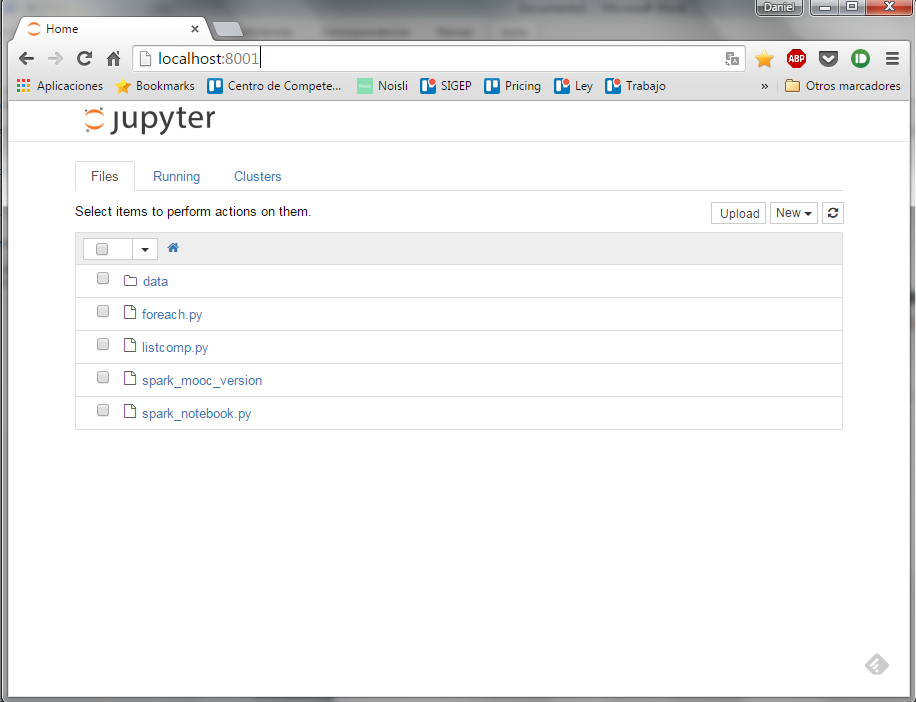
Jupyter es un software donde se pueden editar y ejecutar Notebooks de IPython o python interactivo. Un Notebook es un documento que contiene un conjunto de celdas. Cada celda puede tener texto, en formato MarkDown, o en código Python que se puede ejecutar de forma individual. Cuando se ejecuta el código contenido en una celda, el resultado se muestra en el propio notebook, justo debajo de la celda. Por ejemplo si introducimos en una celda el código python [print 1+ 1] y lo ejecutamos, el resultado será …

Para probar Spark tenemos a descargar el notebook spark_tutorial_student.ipynb que se encuentra disponible en el repositorio mooc-setup de GitHub. Para descargar este fichero en nuestro disco lo más fácil es a través de la opción de “Guardar enlace como …”
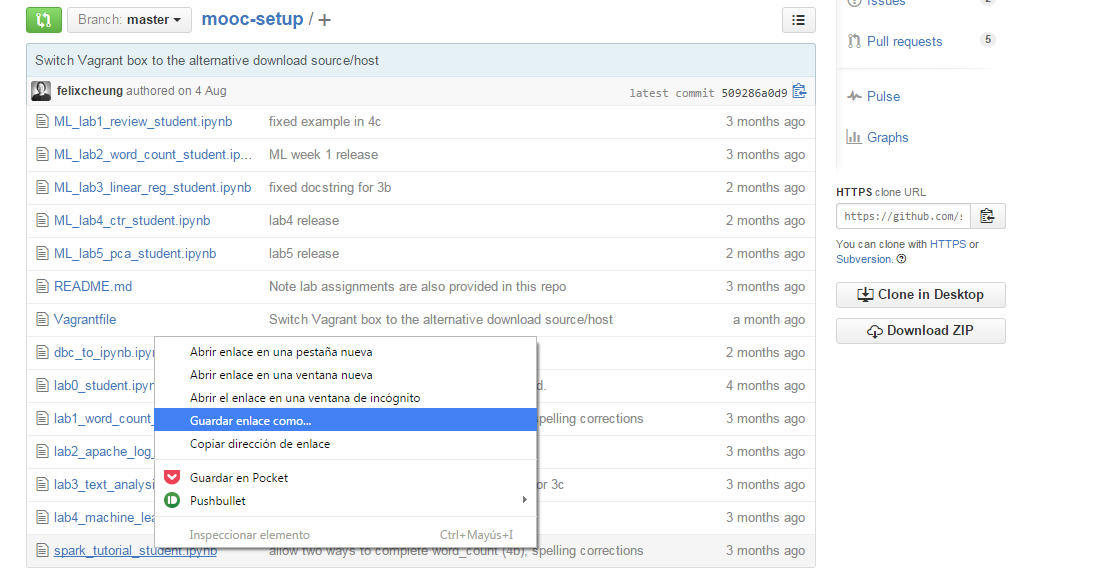
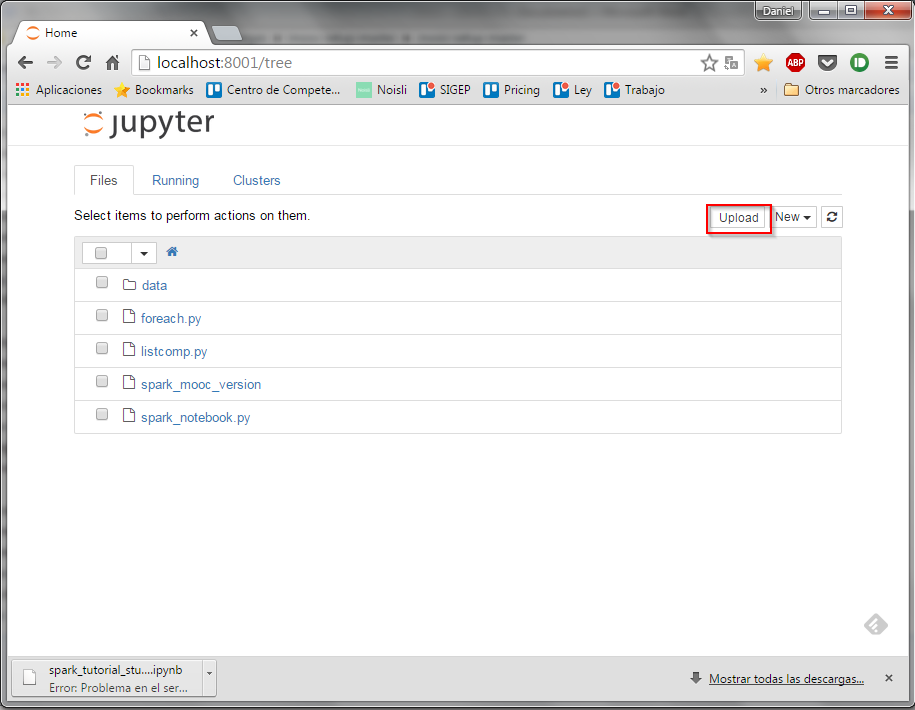
Una vez Jupyter, ya podemos cargar este notobook pulsando el botón upload …
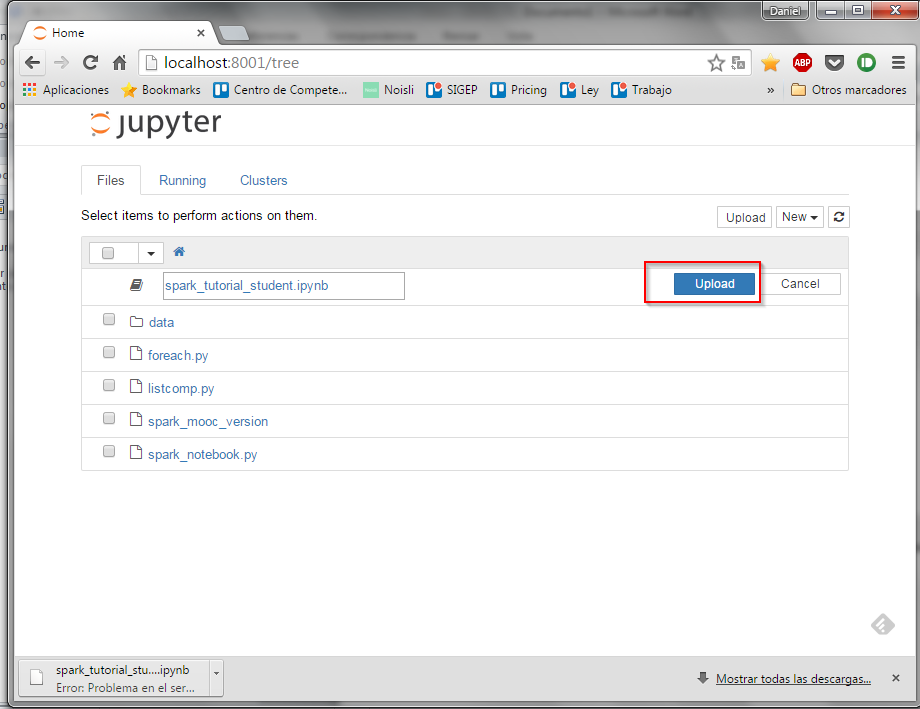
Y volvemos a pulsar el botón Upload, está vez en color azul:
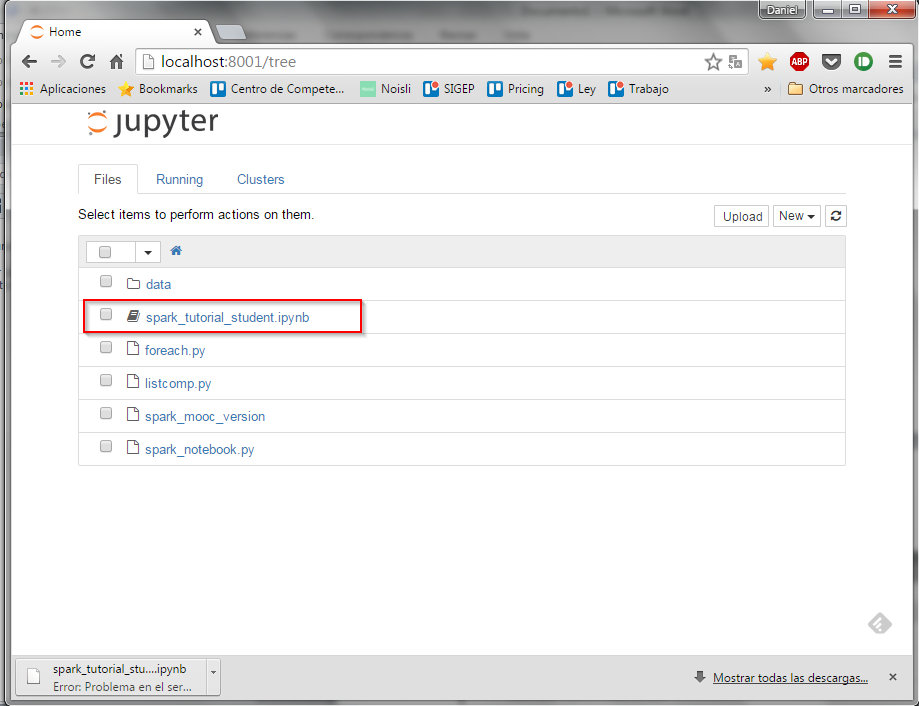
Solo nos queda hacer doble click sobre el notebook para que aparezca una nueva ventana:
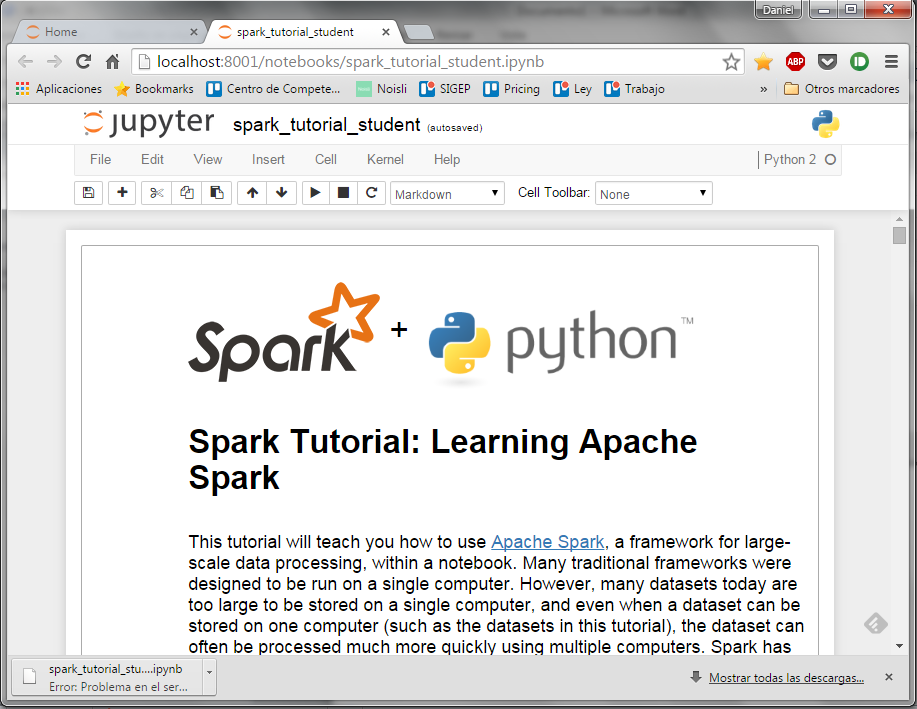
Para seguir el tutorial de Spark se deben de ejecutar cada una de las celdas de este notebook, leyendo atentamente los textos explicativos. Para ejecutar una celda, primero hay que seleccionarla haciendo click sobre ella … (la celda se muestra con un recuadro verde)
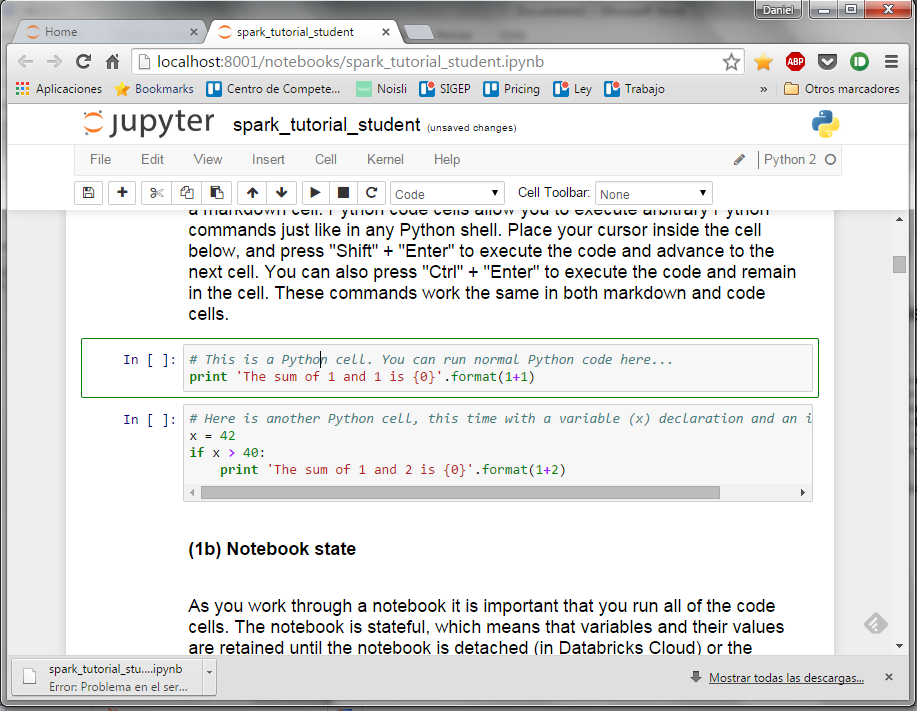
Y pulsar el botón de ejecución …
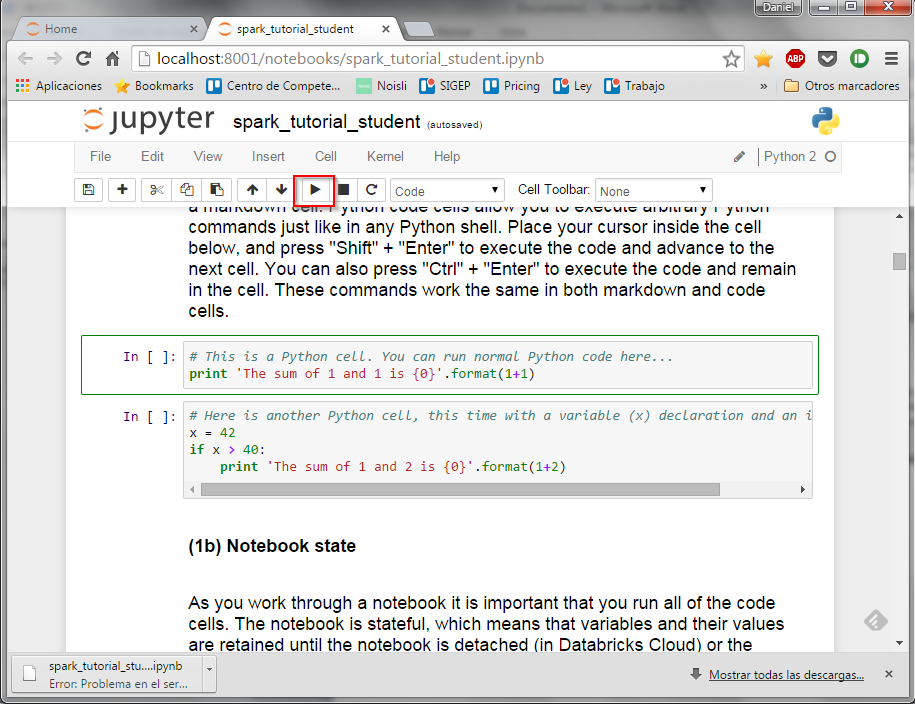
Hasta que lleguemos al final… También se pueden ejecutar otros notebooks de este repositorio, aunque la mayoría requiere que introduzcamos código en python. En especial es muy interesante hacer los notebook ‘lab0_student.ipynb’ y ‘lab1_word_count_student.ipynb’. El resto es un poco más complicado pero os animo a que lo intentéis. Por último, comentaros que para cerrar la máquina virtual simplemente se deberá ejecutar la opción “Apagar” o pulsar Control-F
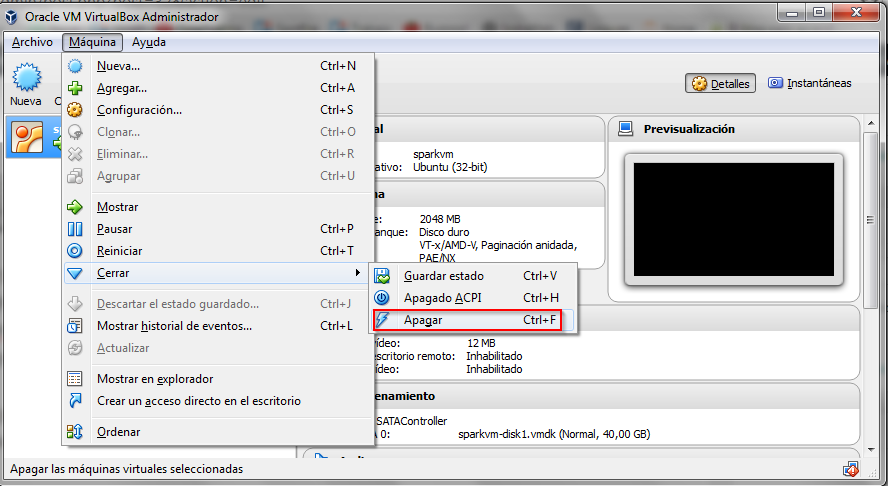
Espero que lo hayáis encontrado interesante…